

So erstellst du die robots.txt
Keine Artikel mehr verpassen? Jetzt Newsletter abonnieren »
Level: Beginner
Als treue Leserin oder treuer Leser unseres Newsletters ist dir der Begriff robots.txt sicher schon mal untergekommen. Du weißt bestimmt, dass sie für das Crawling & Indexing deiner Website wichtig ist, aber weißt du überhaupt, wie du die robots.txt erstellst und hochlädtst? Wir erklären dir heute, wie du die robots.txt-Datei erstellst und welche Anweisungen du geben kannst. Unsere Informationen haben wir von Semrush.
Die robots.txt ist eine Datei, die sich im Root-Verzeichnis deiner Website befindet (wenn sie denn vorhanden ist). Das Root-Verzeichnis ist die oberste Daten-Ebene deiner Website. Hier befinden sich neben der robots.txt. auch die Sitemap, die .htaccess und weitere Dateien, die für die Darstellung der Inhalte deiner Website nötig sind.
Mit der robots.txt steuerst du die Zugriffe von Web Crawlern auf deine Website. Die Datei ist das erste, was ein Crawler ausliest, wenn er auf deine Seite kommt. Dort bekommt er Anweisungen, ob er die Seite crawlen darf oder nicht.
Du als Websitebetreiber kannst dort Crawler komplett ausschließen, einzelne Crawler ausschließen oder spezielle Seiten für die Crawler ausschließen. Denke aber daran, dass die Anweisungen in der robots.txt eher Empfehlungen als strikte Regeln sind. Die „guten“ Cralwer wie der Googlebot oder Bing Bot werden sich daran halten. „Schlechte“ Bots, wie etwa Spambots, ignorieren diese Angaben in der Regel.
So erstellst du deine Robots.txt
Schritt 1: Datei erstellen
Als erstes erstellst du die Datei. Dazu öffnest du eine neue Datei in einem beliebigen Text Editor oder einem Web Browser. Die Datei muss zwingend „robots.txt“ heißen, andernfalls funktioniert es nicht.
Schritt 2: Anweisungen erteilen
Nun füllst du die Datei mit den Anweisungen, welche du gruppierst. Jede Gruppierung startet mit dem Wortlaut User-agent und enthält folgende Informationen:
- Welche Crawler sind betroffen?
- Welche Verzeichnisse dürfen ausgelesen oder nicht ausgelesen werden?
- Wo ist deine Sitemap zu finden?
Beispiel:

beispielhafte robots.txt
Was genau die verschiedenen Anweisungen bedeutet, lernst du weiter unten im Artikel.
Schritt 3: Datei hochladen
Sobald deine robots.txt- Datei fertig ist, musst du sie in dein Root-Verzeichnis hochladen. Das geschieht über dein Content-Management-System. Leider gibt es hierfür keine allgemeingültige Anleitung. Am besten kontaktierst du die Hosting-Plattform deiner Webseite. Sie gebe dir die beste Auskunft.
Schritt 4: Datei testen
Zunächst testest du, ob deine robots.txt verfügbar ist. Dazu rufst du sie im Inkognito-Modus deines Browsers auf. Wenn sie erscheint, ist sie schon mal richtig hochgeladen.
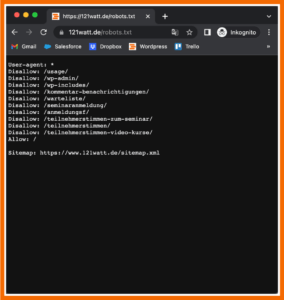
robots.txt der 121WATT
Nun checkst du die Funktion. Dazu musst du die entsprechende Seite für die Google Search Console registriert haben. Wenn das geschehen ist, öffnest du den robots.txt-Tester. Dieser gibt dir Auskunft darüber, ob du alle Anweisungen richtig formuliert hast oder ob es Fehler in der Datei gibt.
Anweisungen
Wir haben dir hier die gängigsten Anweisungen zusammengefasst.
- Der User-Agent
In der ersten Zeile einer Anweisung gibst du an, für welchen User-agent (Crawler) die darauffolgende Anweisung gilt.
Hier findest du eine Liste mit verschiedenen Web Crawlern und User-Aagents.- Beispiele
Hier gilt die Anweisung ausschließlich für den Googlebot:
User-agent: Googlebot
Mit einem * kennzeichnest du, dass alle Crawler gemeint sind:
User-agent: *
- Beispiele
- Disallow
Mit disallow markierst du, welche Verzeichnisse der jeweilige Crawler nicht ansteuern darf.- Beispiele
Um deinen Blog vom Crawling auszuschließen, schreibst du Folgendes:
Disallow: /blog
Um alle Verzeichnisse auszuschließen, genügt ein /:
Disallow: /
- Beispiele
- Allow
Der Befehl Allow erlaubt dem Crawler ein bestimmtes Unterverzeichnis zu Crawlen, selbst wenn das übergeordnete Verzeichnis per disallow ausgeschlossen ist:- Beispiel
Der Blog soll ausgeschlossen werden, bis auf die Artikel zur Suchmaschinenoptimierung:
Disallow: /blog
Allow: /blog/suchmaschinenoptimierung
- Beispiel
- Sitemap
Am Ende deiner robots.txt fügst du noch den Link zu deiner Sitemap ein (sofern sie vorhanden ist). Die Bezeichnung stellst du voran:
Sitemap: https://beispiel.com/sitemap.xml
Eine robots.txt, wie wir sie hier beschrieben haben, könnte so aussehen:
User-agent: Googlebot
Disallow: /blog
User-agent: *
Disallow: /blog
Allow: /blog/seo
Sitemap: https://beispiel.com/sitemap.xml
🔍 Weitere Anweisungen und Erklärungen zur robots.txt findest du bei Semrush.
Wie hilfreich ist dieser Artikel für dich?
Noch ein Schritt, damit wir besser werden können: Bitte schreibe uns, was dir am Beitrag nicht gefallen hat.
Noch ein Schritt, damit wir besser werden können: Bitte schreibe uns, was dir am Beitrag nicht gefallen hat.
Vielen Dank für dein Feedback! Es hilft uns sehr weiter.

gar nicht hilfreich

weniger hilfreich

eher hilfreich

sehr hilfreich

ich habe ein anderes Thema gesucht